
지난 포스팅은 프로젝트의 전반적인 주제인 이미지의 의미적 분할에 대해서 알아봤습니다. 이번 포스팅에서는 의미적 분할을 하기 위해 필요한 이미지를 어떻게 읽어오고, 적절하게 전처리를 할지 OpenCV라는 패키지를 통해 알아보도록 하겠습니다.
Semantic Segmentation (의미적 분할)
이미지 분할(Image Segmentation)이란? - 컴퓨터 비전(Computer vision)의 한 분야 - 이미지를 몇 개의 영역으로 구분하는 작업 - 이미지의 공간 영역, 객체들을 픽셀 수준에서 구분하여 라벨을 지정하는 작
data-science-note.tistory.com
OpenCV 소개

- 영상 또는 이미지 처리 소스들을 모아 놓은 패키지 (링크 : https://github.com/opencv/opencv-python)
- 이미지 처리 알고리즘이 최적화 되어 있어 사용자가 알고리즘 활용에만 집중 가능
OpenCV는 API가 잘 정리되어 있어서 이미 정의된 함수만 가져와서 사용해도 무방하지만, 알고리즘 내부에 대한 이해가 있으면 보다 정확하게 사용할 수 있으니 차근차근 알아가보도록 하겠습니다!
OpenCV 설치
- 저의 사용 환경 : Windows 10, Python 3 버전 (이외에도 다양한 환경에서 OpenCV를 사용할 수 있습니다)
- cmd 명령창에서 pip 사용하여 OpenCV 패키지 설치
# pip 명령 사용
pip install opencv-python- 설치 완료되었는지 확인하기 위해 Python에서 import 및 설치 버전 확인
- 아래 코드의 cv2가 OpenCV를 가리킴
- scikit-learn이 sklearn인 것처럼 패키지 이름과 import에 쓰이는 이름이 다름을 주의!
# 설치 후 OpenCV 버전 확인
import cv2
print(cv2.__version__) # '4.6.0'그럼 이제 OpenCV 패키지를 사용해 이미지를 읽어보도록 하겠습니다.
이미지 읽기 (cv2.imread)
cv2.imread(fileName, flags)
- Parameters
- fileName : 이미지 파일의 경로
- flags : 이미지 파일을 읽을 때의 옵션
- Returns : 이미지 객체 행렬
- Return type : numpy.ndarray
fileName : 이미지 파일의 경로
- OpenCV로 읽기 가능한 이미지 포맷
- bmp / dib / jpeg / jpg / jpe / jp2 / png / webp / pbm / pgm / ppm / pxm / pnm / sr / ras / tiff / tif / exr / hdr / pic
이미지 처리를 하기 위해서는 이미지 파일이 있어야 하고 파일을 컴퓨터 메모리에 올려야 합니다. 이 때 사용가능한 API가 바로 OpenCV의 cv2.imread 입니다. 평소에 볼 수 있는 이미지 포맷인 jpg, png 외에 다양한 포맷들도 지원하는 것을 알 수 있습니다.
flags : 이미지 파일을 읽을 때의 옵션
- -1 : 원본 (Unchanged) = cv2.IMREAD_UNCHANGED
- 0 : 단일 채널 (Grayscale) = cv2.IMREAD_GRAYSCALE
- 1 : 3 채널 (BGR Color) = cv2.IMREAD_COLOR
- 2 : 16 비트는 16 비트로, 32 비트는 32 비트로, 그 외에는 8 비트로 읽음
- 16 : 단일 채널 & 이미지 크기 1/2로 축소
- 17 : 3 채널 & 이미지 크기 1/2로 축소
- 32 : 단일 채널 & 이미지 크기 1/4로 축소
- 33 : 3 채널 & 이미지 크기 1/4로 축소
- 64 : 단일 채널 & 이미지 크기 1/8로 축소
- 65 : 3 채널 & 이미지 크기 1/8로 축소
그럼 이제 이미지를 다운로드 받아 cv2.imread로 읽어보도록 하겠습니다. 여기서는 Cityscapes 데이터셋을 받아서 사용합니다 (Cityscapes Dataset 링크). 그 중에서도 함부르크에서 촬영 된 hamburg_000000_000042_leftImg8bit.png 파일을 읽어오겠습니다.
# 이미지 파일 경로
img_dir = 'D:/leftImg8bit_trainvaltest/leftImg8bit/train/hamburg'
fname = 'hamburg_000000_000042_leftImg8bit.png'
import os
img_gray = cv2.imread(os.path.join(img_dir, fname), flags = 0)
img_color = cv2.imread(os.path.join(img_dir, fname), flags = 1)
img_color_reduce = cv2.imread(os.path.join(img_dir, fname), flags = 17)
print(0, img_gray.shape) # 0 (1024, 2048) : Gray scale
print(1, img_color.shape) # 1 (1024, 2048, 3) : BGR (Blue, Green, Red)
print(17, img_color_reduce.shape) # 17 (512, 1024, 3) : Half-sized BGRcv2.imread로 읽어온 이미지는 이미지 높이, 너비, 채널의 차원을 가진 배열 (numpy.ndarray)로 반환됩니다. 여기서 채널이란 이미지를 구성하는 픽셀의 특성(feature)을 가리킵니다. 컬러 이미지는 3 채널 R(ed)G(reen)B(lue) 또는 4 채널 C(yan)M(agenta)Y(ellow)(Blac)K, 흑백 이미지는 보통 한 개의 채널만 갖습니다.
※ RGB 와 CMYK 비교

이미지 시각화
아래의 그림은 Matplotlib 시각화 패키지를 사용해서 cv2.imread로 읽은 이미지를 시각화 한 결과입니다.
단일 채널 (Grayscale)
# Grayscale
plt.imshow(img_gray, cmap = 'gray'); plt.show()
3 채널 (Color)
cv2.imread를 사용해 읽어온 이미지를 Matplotlib으로 시각화 할 때는 채널 순서를 주의해야 합니다. cv2.imread는 3 채널 순서를 BGR로 읽어오는 반면, Matplotlib은 시각화를 할 때 RGB 인식해서 읽어오기 때문에 아래와 같이 채널 순서를 반대로 변환하는 과정이 필요합니다.
- 채널 순서 변경 (BGR → RGB)
- cv2.cvtColor(이미지 객체 행렬, cv2.COLOR_BGR2RGB)
# BRG -> RGB로 변경
img_color = cv2.cvtColor(img_color , cv2.COLOR_BGR2RGB)
img_color_reduce = cv2.cvtColor(img_color_reduce, cv2.COLOR_BGR2RGB)# RGB
plt.imshow(img_color); plt.show()
# RGB & Half size
plt.imshow(img_color_reduce); plt.show()

이미지 처리
- 다양한 기법의 이미지 변환 방법을 적용하여 이미지 전처리(Preprocess), 데이터 증식(Data Augmentation) 등 프로젝트 분석 과정에 적합한 데이터를 취득
- 이미지 처리 종류
- 이미지 더하기
- 이미지 필터링 : 블러링, 샤프닝
- 기하학적 변환 : 이동, 확대/축소, 회전
이미지 처리 1 : 이미지 더하기 (cv2.add 또는 cv2.addWeighted)
cv2.add(img1, img2)
- Parameters
- img1, img2 : 더하기 대상이 되는 이미지 객체 행렬
- Returns : 더하기 이미지 객체 행렬
- Return type : numpy.ndarray
cv2.addWeighted(img1, weight1, img2, weight2, gamma)
- Parameters
- img1 : 첫번째 이미지 객체 행렬
- weight1 : 첫번째 이미지 가중치
- img2 : 두번째 이미지 객체 행렬
- weight2 : 두번째 이미지 가중치
- gamma : 가중합 결과에 추가적으로 더하는 값
- Returns : 가중 더하기 이미지 객체 행렬
- Return type : numpy.ndarray
두 개의 이미지를 하나로 합치는 처리 과정을 코드로 살펴보겠습니다. 우선, 여기서 사용할 도로 이미지와 여기에 해당하는 Segmentation 라벨 이미지를 시각화하여 확인합니다.
# 이미지 읽기
base_img = cv2.imread(
"D:/leftImg8bit_trainvaltest/leftImg8bit/train/hamburg/hamburg_000000_000042_leftImg8bit.png",
flags = 1 # BGR
) # 도로 이미지
seg_img = cv2.imread(
"D:/gtFine_trainvaltest/gtFine/train/hamburg/hamburg_000000_000042_gtFine_color.png",
flags = 1
) # Segmentation 라벨 이미지
# BGR -> RGB
base_img = cv2.cvtColor(base_img, cv2.COLOR_BGR2RGB)
seg_img = cv2.cvtColor( seg_img, cv2.COLOR_BGR2RGB)
# 시각화
import matplotlib.pyplot as plt
fig, subs = plt.subplots(ncols = 2, figsize = (20, 5))
for sub, img in zip(subs.flatten(), [base_img, seg_img]): sub.imshow(img)
plt.show()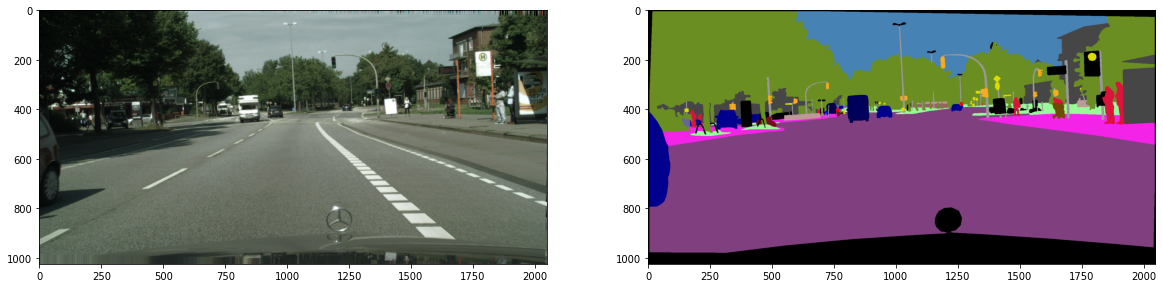
다음 코드는 두 개의 이미지를 더하기 하는 OpenCV 코드 입니다.
# 더하기
added_img = cv2.add(base_img, seg_img)
# 가중 더하기 (도로 이미지 25%, Segmentation 라벨 이미지 75% 가중치를 줌)
weighted_img = cv2.addWeighted(base_img, .25, seg_img, .75, gamma = 0)
# 시각화
fig, subs = plt.subplots(ncols = 2, figsize = (20, 5))
for sub, img in zip(subs.flatten(), [added_img, weighted_img]): sub.imshow(img)
plt.show()
왼쪽 그림과 같이 단순하게 더하기 연산만 한 경우 전반적으로 많이 밝게 표현되는 것을 볼 수 있습니다. 이는 단순 합을 할 경우 각 채널이 갖게 되는 값 자체가 누적돼 커지기 때문에 그만큼 밝게 보이기 때문입니다.
반면 가중 더하기 한 오른쪽 그림은 두 이미지가 적절하게 잘 겹쳐져서 표현되는 것을 볼 수 있습니다. 이 경우는 각각의 이미지에 0.25와 0.75를 곱해서 더해주었기 때문에 원래의 밝기를 유지할 수 있습니다.
다음 포스팅에서는 이미지 처리 종류 중 남은 이미지 필터링과 기하학적 변환에 대해서 알아보도록 하겠습니다.

'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| OpenCV를 사용한 이미지 이진화 (cv2.threshold, cv2.adaptiveThreshold) (0) | 2023.02.14 |
|---|---|
| Fully Convolutional Networks (FCN) (0) | 2023.01.11 |
| 합성곱 신경망 (Convolutional Neural Networks ; CNN) (0) | 2022.11.29 |
| OpenCV를 사용한 이미지 처리 - 블러링 (cv2.blur, cv2.GaussianBlur) (0) | 2022.11.21 |
| Semantic Segmentation (의미적 분할) (0) | 2022.08.28 |