반응형
이미지 분할(Image Segmentation)이란?
- 컴퓨터 비전(Computer vision)의 한 분야
- 이미지를 몇 개의 영역으로 구분하는 작업
- 이미지의 공간 영역, 객체들을 픽셀 수준에서 구분하여 라벨을 지정하는 작업

위 그림에서 첫번째 Classification (분류)는 입력 이미지의 전반적인 클래스(대체로 하나의 클래스)를 예측하는 것이 목적이다. 두번째 Object Detection (객체 탐지)는 입력 이미지 내 모든 물체의 클래스와 위치를 예측하는 것이 목적이다. 세번째 Segmentation (분할)은 입력 이미지 내 모든 픽셀의 클래스를 예측하는 것이 목적이다.
이미지 분할(Image Segmentation)의 종류
- 의미적 분할 (Semantic segmentation)
- 객체 분할 (Instance segmentation)
- 판옵틱 분할 (Panoptic segmentation)
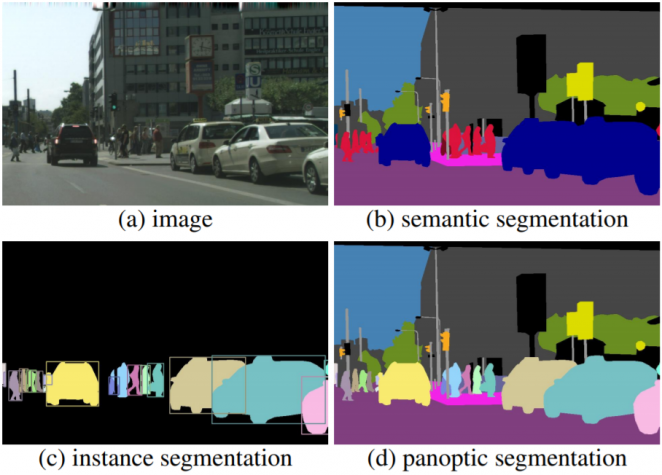
| Semantic (의미적) | Instance (인스턴스) | Panoptic (판옵틱) | |
| 클래스 구분 가능 | O | △ (형태가 뚜렷한 경우 구분) |
O |
| 객체 구분 가능 | X | O | O |
1. Semantic Segmentation (의미적 분할)
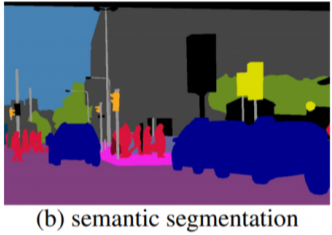
- 이미지를 구성하는 모든 픽셀에 대해 클래스를 예측
- 분할된 이미지의 클래스를 구분할 수 있지만, 동일한 클래스의 영역이 겹쳐지는 경우(ex. 군중) 같은 영역으로 인식하기 때문에 각 객체를 구분할 수는 없음
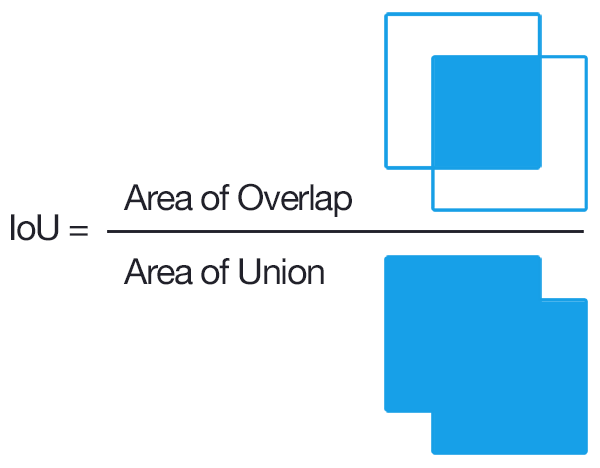
- 대표적인 평가지표는 MIoU (Mean Intersection over Union)로, 자카드 지수(Jaccard index)라고도 함

2. Instance Segmentation (객체 분할)

- 객체 탐지(Object detection)처럼 객체를 구분하는 작업을 픽셀 수준에서 진행
- 의미적 분할과 다른 점은 겹쳐져 있는 동일한 클래스의 객체 구분이 가능
- 모든 픽셀에 라벨을 지정하지 않고, 관심 영역(RoI; Region of Interest)에 대해서 라벨을 예측
- 대표적인 평가지표는 MAP (Mean Average Precision)
3. Panoptic Segmentation (판옵틱 분할)
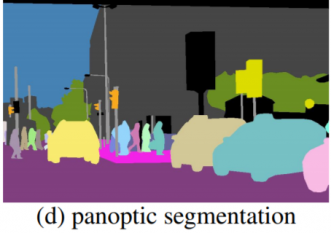
- "의미적 분할 + 객체 분할"이라 보면 됨
- 대표적인 평가지표는 PQ (Panoptic Quality) = SQ (Semantation Quality) * RQ (Recognition Quality)
반응형
Semantic Segmentation 관련 데이터셋
1. Cityscapes

- 도시 길거리 이미지
- 30개 클래스
- 도로(road) / 보행로(sidewalk) / 사람(person) / 오토바이(motorcycle) / 자전거(bicycle) / 건물(building) / 기둥(pole) / 교통표지(traffic sign) / 식물(vegetation) / 하늘(sky) 등
2. CamVid

- 도시 길거리 이미지
- 32개 클래스
- 도로(Road) / 차선(LaneMkgsDriv) / 자동차(Car) / 건물(Building) / 나무(Tree) / 식물(VegetationMisc) / 기둥(Column_Pole) 등

이미지 분할을 위한 라벨링 도구
- V7, Labelbox, ScaleAI, SuperAnnotate, DataLoop
Semantic Segmentation 관련 딥러닝 모델
| 모델명 | 연도 | 논문명 (링크) |
| FCN (Fully Convolutional Network) |
2015 | Fully Convolutional Networks for Semantic Segmentation (Long et al.) |
| U-net | 2015.05 | U-Net: Convolutional Networks for Biomedical Image Segmentation (Ronneberger et al.) |
| ParseNet | 2015.06 | ParseNet: Looking Wider to See Better (Liu et al.) |
| DeepLab | 2016.06 | DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs (Chen et al.) |
| PSPNet (Pyramid Scene Parsing Network) |
2016.12 | Pyramid Scene Parsing Network (Zhao et al.) |
반응형
'인공지능 > 컴퓨터 비전' 카테고리의 다른 글
| OpenCV를 사용한 이미지 이진화 (cv2.threshold, cv2.adaptiveThreshold) (0) | 2023.02.14 |
|---|---|
| Fully Convolutional Networks (FCN) (0) | 2023.01.11 |
| 합성곱 신경망 (Convolutional Neural Networks ; CNN) (0) | 2022.11.29 |
| OpenCV를 사용한 이미지 처리 - 블러링 (cv2.blur, cv2.GaussianBlur) (0) | 2022.11.21 |
| OpenCV를 사용한 이미지 처리 (설치, 읽기, 시각화) (2) | 2022.11.19 |